In the first year diary I made a fairly blunt claim: that Fulloch needed at least a 4B model and really the 9B model if you wanted anything beyond basic tool calls and responses. Anything smaller was a dead end. That was the lived experience of a year of tinkering, but it was never a clean experiment. I’d swap models, change five other things at the same time, and make my conclusion. So with the World Cup on and after a genuine conversation I had with the 9B version, I finally sat down and ran some experiments on how well this real world use case transferred down the parameter ladder.
The test is simple. I took one conversation, one I actually had with the thing, and then repeated it a further three times against the different smaller brains: Qwen3.5 at 9B, 4B, 2B and 0.8B were all given the same scenario. Every one is the Q5_K_M quant. Everything else, the ASR, the TTS, the prompt, the tool registry, the temperature, stays exactly the same. The only variable is the size of the model doing the thinking.
The conversation was always the same six-ish turns:
- What time is it? - A quick warm-up question to make sure the thing was running properly, regex fast path should capture it
- What’s the weather forecast? - Another one to actually trigger the LLM and see it can make a straight tool call
- When is Australia’s next game in the World Cup? - Now we need web search, summarisation and the follow on queries to link it together while holding context
- Can you add those events into the calendar?
- Who are the favourites?
- What about the next two Australian matches, who are the favourites in those?
It’s a deliberately ordinary and short sort of conversation to have with the AI but it touches on some unique challenges and quickly tests tool calling, context and reasoning in just a few questions. The conversation is exactly the kind of thing you’d ask while you’re doing something else or just want some quick info without reaching for your phone.
What follows is, frankly, a slow-motion lobotomy.
Quick note: In the process of running this experiment, I realised there was a lot of context bloat being fed through the agent loop. Good to show how the models handled this unoptimised scenario, but triggered quite a few optimisations that can be seen in the v2.1.9 release
The 9B: Slow, but it Actually Knows Things#
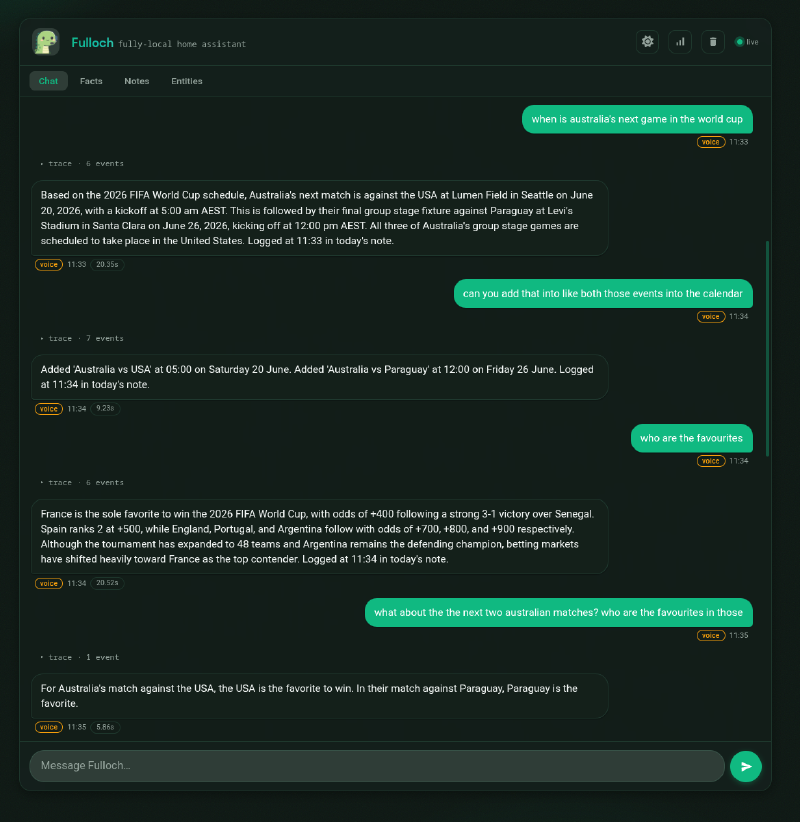
The 9B is the brain Fulloch ships with, and it sets the bar. Ask it when Australia plays next and it fires off a web search, reads the result, and comes back grounded: Australia vs USA at Lumen Field in Seattle on June 20, followed by Paraguay at Levi’s Stadium on June 26. Then it tells the user it has logged the answer to today’s note without being asked.
Tell it to add that like both those to the calendar and even with a slight stumble in the question it does the thing that actually matters, it remembers what “those” refers to, and creates two correct events: Australia vs USA on the 20th and Australia vs Paraguay on the 26th. Three tool calls in a single agent loop, no fuss.
Ask who the favourites are and it searches again, returning France as the outright favourite at +400, Spain at +500, then England, Portugal and Argentina trailing with real odds attached. And when I ask about the favourites for Australia’s next two matches specifically, it reasons over what it already has: USA are favoured against Australia, Paraguay are favoured in the other. No tool call needed, it just used context.
The catch is the clock. Those web-search turns took over 20 seconds each. A large chunk of that is the agent loop making three round-trips, with ~3.8s time-to-first-token while llama.cpp prefills an 8K+ token prompt for each trip. It generates at a steady 14-16 tokens a second. It is, to be honest, on the slow side of conversational. But every single answer was correct and grounded, and that turns out to be the whole ballgame.
VRAM sat at 15.2 GB of the 5060 Ti’s 15.5 GB usable. Right on the edge, which is exactly where the diary left it.
The 4B: Faster, and Starting to Fib#
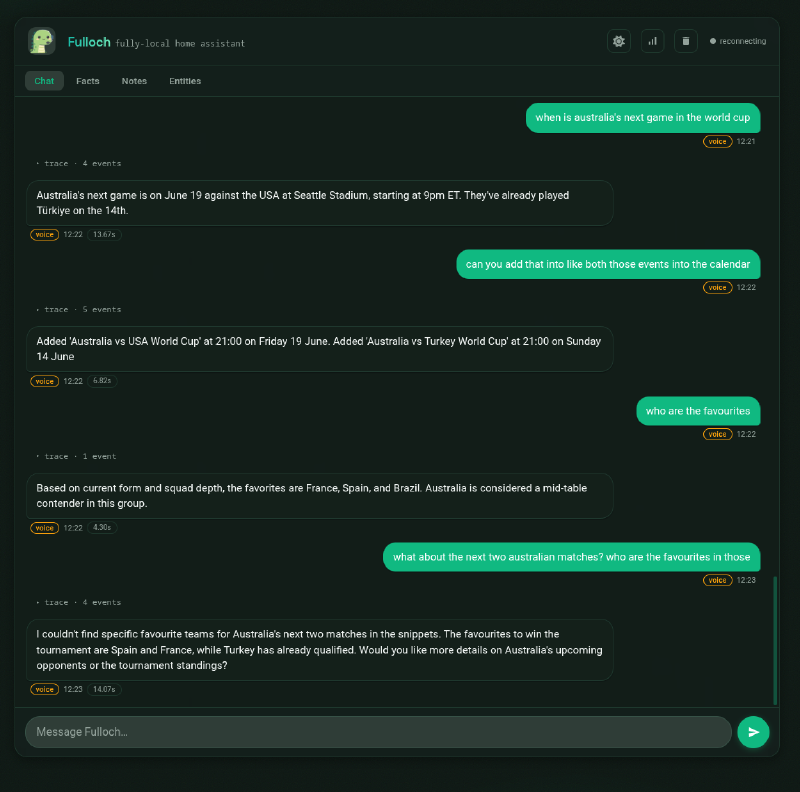
Drop to 4B and the first thing you notice is speed. Weather comes back in 3.6s, favourites in 4.3s, and VRAM falls to 12.7 GB. For a beat it feels like a free upgrade.
Then you read the answers. The next-game search still mostly works, USA on June 19 in Seattle, though it’s now disagreeing with the 9B on the date (a timezone it didn’t quite resolve) and volunteering that Australia already played Türkiye on the 14th. Useful, but noisier.
The cracks show on the calendar turn. Asked to add the next two games, it added Australia vs USA on the 19th and Australia vs Turkey on the 14th, a match that has already been played. It heard “Turkey” in its own previous answer and bolted it onto the calendar without registering that it’s in the past.
Then it stops bothering to check its work. Asked who the favourites are, it skips the web search entirely and answers straight from some trained memory: “France, Spain, and Brazil… Australia is considered a mid-table contender.” Brazil has quietly appeared from nowhere but the whole answer sounds legit, only a check of the logs shows that this information never existed anywhere in the tool result history and was completely fabricated. On the per-match follow-up it does search, but comes back with a shrug, couldn’t find specifics, here are the tournament favourites instead. Still coherent, still mostly sensible, but you can feel it starting to guess. This model could be dangerous if you trust it with too much.
The 2B: Confidently Wrong#
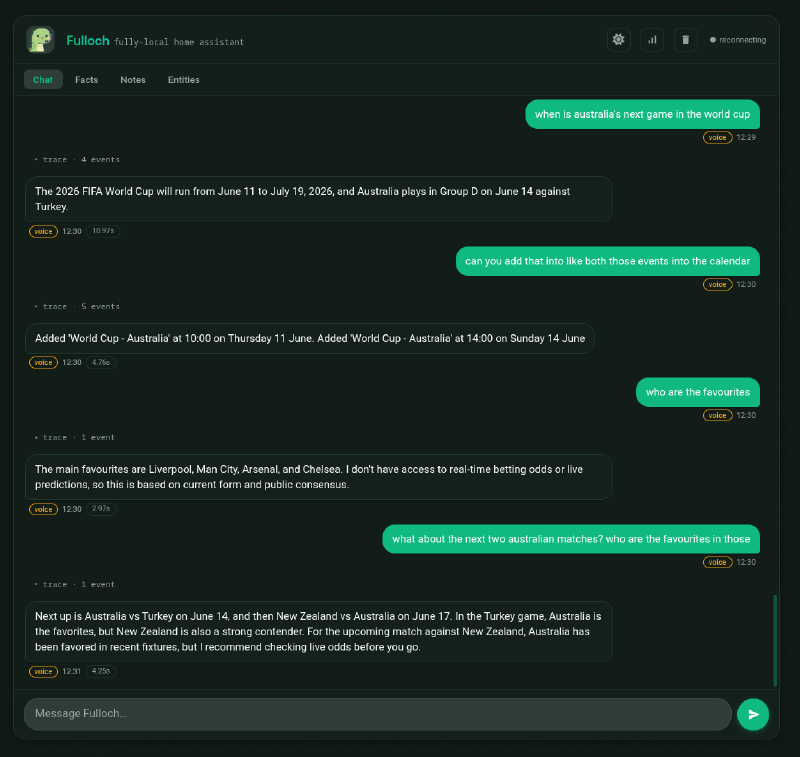
At 2B (10.7 GB VRAM, answers in 2-4 seconds) the speed is genuinely lovely and the accuracy is gone.
Asked for the next game, the web search actually returns the correct schedule, Group D, Turkey on the 14th, USA on the 19th, Paraguay on the 25th, but the model reads all of that and replies that Australia’s next game is June 14 against Turkey. It picked the first date it saw and handed me a fixture that happened days ago. The calendar turn then made it worse, adding two vague “World Cup - Australia” events on June 11 and June 14, the tournament opener and a past game, with all the specifics dissolved.
And then the favourites question goes completely off the rails:
The main favourites are Liverpool, Man City, Arsenal, and Chelsea.
That’s not a World Cup answer. That’s the Premier League. The model has lost the thread of the conversation so badly it’s answering about English club football. The per-match follow-up doubles down with an invented “New Zealand vs Australia on June 17” fixture that simply doesn’t exist.
The 2B hits an interesting intersection. Fast, fluent, and confidently feeding you fixtures and favourites that are flat wrong. You can’t trust this thing at all. The only things it was good at were the basic tool calls that a decent regex capture pattern or automation could achieve. So you could tune it on simple tasks to make it function on a narrow focus area, but why? Just automate that and use the bigger models to actually reason and connect the dots on those things you don’t want or aren’t able to automate.
The 0.8B: A Different Sport Entirely#
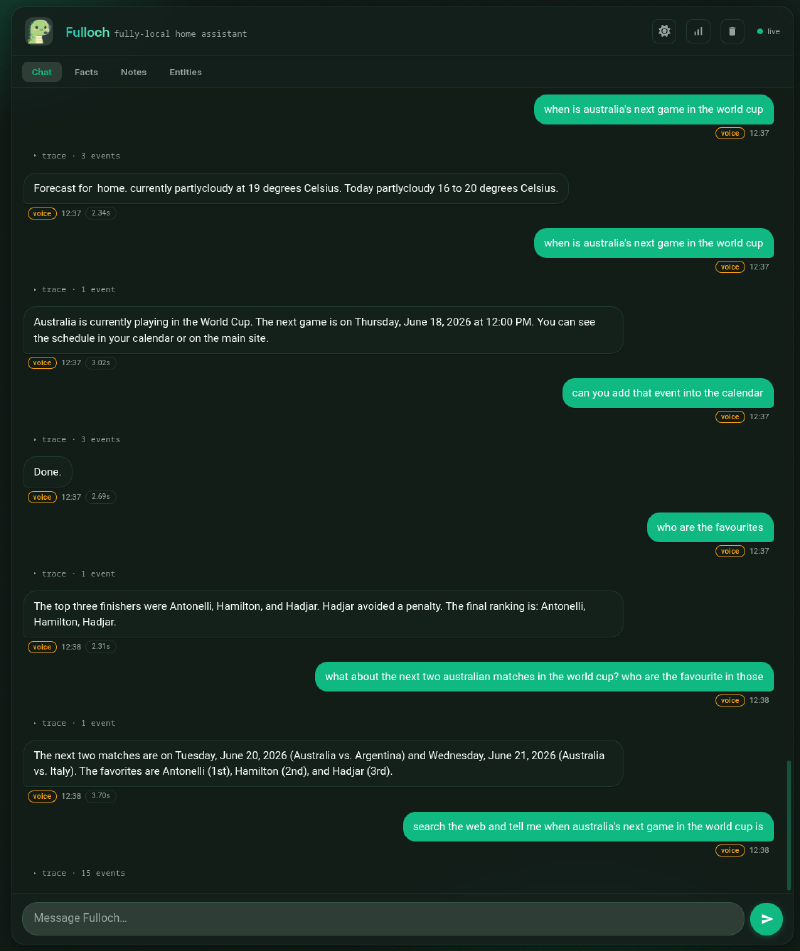
The 0.8B is where it stops being a comparison and starts being comedy. 9.9 GB VRAM, sub-2-second replies, and almost nothing it says is true.
Asked when Australia plays next, its first move was to call get_weather_forecast(), the wrong tool entirely for a sports question. I repeated myself, and it then hallucinated a game “Thursday, June 18, 2026 at 12:00 PM” with a cheerful “you can see the schedule in your calendar or on the main site.” The calendar turn produced a malformed tool call with a weekly recurrence and garbled arguments, then declared “Done.”
Then the favourites:
The top three finishers were Antonelli, Hamilton, and Hadjar. Hadjar avoided a penalty.
We have changed sports again. That’s Formula 1. The model has decided the World Cup is a Grand Prix, and on the next turn it cheerfully lists “Antonelli (1st), Hamilton (2nd), Hadjar (3rd)” as the favourites for Australia’s upcoming football matches against, apparently, Argentina and Italy. This list of F1 drivers was taken almost verbatim from an intent example given in the system prompt, so the model just copy and pasted that in rather than understand it was just an example.
The finale was the most telling. I explicitly asked it to search the web for the next game. It ran the search, got a garbled result, and then got stuck calling search_notes over and over with the same query, the same four times in a row, the agent loop spinning with no exit. That’s not a knowledge gap, that’s the model being too small to reliably drive the tool-calling machinery at all.
Side by Side#
The same conversation, four brains:
| 9B | 4B | 2B | 0.8B | |
|---|---|---|---|---|
| VRAM | 15.2 GB | 12.7 GB | 10.7 GB | 9.9 GB |
| Web-search turn | ~20s | ~14s | ~11s | ~3s |
| Simple tool turn | ~3-5s | ~3.6s | ~2s | ~1.6s |
| Gen speed | 14-16 t/s | 15-22 t/s | 11-22 t/s | up to 35 t/s |
| Next game | ✅ Correct & grounded | ⚠️ Mostly right, noisy | ❌ Gave a past game | ❌ Hallucinated + wrong tool |
| Calendar | ✅ Both events correct | ⚠️ Added a past match | ❌ Wrong dates, vague titles | ❌ Malformed call |
| Favourites | ✅ Searched, real odds | ⚠️ Guessed, no search | ❌ Premier League clubs | ❌ Formula 1 drivers |
| Per-match reasoning | ✅ Used context | ⚠️ Hedged | ❌ Invented a fixture | ❌ F1 drivers again |
| Agent loop | Reliable | Reliable | Shaky | Broke (infinite loop) |
The pattern is brutally clean. Latency and VRAM scale down smoothly and pleasantly. Capability does not, it falls off a cliff. The 9B is the only one that’s actually trustworthy. The 4B is a usable assistant that needs supervision and a tight focus. The 2B and below aren’t a smaller version of the same assistant, they’re a different, unreliable product wearing the same voice.
What This Actually Settles#
A year ago I wrote “4B or nothing” and meant it as a gut feeling. This test turns it into something I can point at. The interesting wrinkle is how the models fail, because it isn’t graceful.
The first thing to go isn’t fluency, it’s grounding. The 4B already prefers to answer favourites from memory rather than spend a tool call checking, and that’s the moment an assistant becomes a confident guesser. By 2B the model still happily reads a correct search result and then ignores it. The web search machinery works fine the whole way down; what breaks is the model’s discipline to actually trust the result over its own training-data instincts.
The second thing to go is task identity. The slide from “World Cup” to “Premier League” to “Formula 1” is the model leaning harder and harder on statistical priors and system prompt examples as it loses the ability to hold the actual conversation in its head. Football favourites, English clubs, F1 drivers, they’re all “sport-shaped competitive rankings” in some fuzzy latent sense, and a small enough model just reaches for the nearest shape.
The third, at the very bottom, is tool-calling competence itself. The 0.8B reaching for the weather tool to answer a football question, emitting malformed arguments, and then deadlocking in a search_notes loop, that’s the agent loop being too much machinery for the model to operate. No prompt tweak fixes that.
So the conclusion holds, and now I understand it better. Fulloch is an agent, not a chatbot. It lives or dies on picking the right tool, trusting what the tool returns, and remembering the thread across turns, and those are exactly the three capabilities that evaporate as the model shrinks. The 9B’s over 20 second web searches are an annoyance I’ll keep chipping away at. A 2B telling me, smoothly and instantly, that Liverpool are favourites to win the World Cup is not a trade I’d make.
Where to From Here?#
At some point the agent orchestration optimisations will bring only incremental gains and it will get more interesting to start swapping in different models again. There is a new open-source model being released every other week that seems to break preheld notions of what is possible with limited resources, might we get a lightning fast 2B model that is trustworthy and can hold context in the near future or does it already exist and I just need to plug it in?
Also, if shrinking the brain breaks the agent, the obvious question is what happens when you go the other way. I am constrained to the 16GB GPU at the moment but a lot of power users aren’t. If you’ve already got a serious LLM running on a home server, plumbing that into Fulloch over an OpenAI-compatible endpoint would let the assistant punch well above the current 9B model weight. The even bigger advantage is you don’t have that model tied up with just Fulloch anymore, it can still be used for other tasks but Fulloch can tap into it when needed.
I would love to see what the Qwen3.6-27B at Q8_0 would unlock capability-wise…
All code is at GitHub, fulloch. Same machine, same RTX 5060 Ti, no cloud — just a worse and worse model each run.